Why You Should Learn jq in 2024
Discover why learning jq isn't just about boosting your productivity, it's about becoming a more curious developer
The chances are that if you are a modern developer or if you’re starting out, you probably don’t know what jq is, and that’s why I’m writing this post. It won’t take long to explain what jq is, so let’s just get that out of the way.
jq could be labeled a command line tool, but in truth it‘s a very “high-level lexically scoped functional programming language” (at least according to Wikipedia) that has been around for over a decade. The whole thing is based around JSON and helping you manipulate it in the terminal quickly, which may seem dull or not very useful to the untrained, but let me show you why this goes so hard.
A great way to experience jq yourself is to follow their short tutorial but I wanted to give a more personal example. Recently I built a CLI for Pinata that lets you upload, access, and manage your files from the terminal. One simple command you can run is pinata files list -a 5 to display a list of your most recent uploads (limiting the amount to 5 items for now), and the output looks like this.
{
"files": [
{
"id": "01927e06-6f36-7208-adb9-8cdd53ce1c98",
"name": "pgdata.tar.gz",
"cid": "bafybeicvzjxfbo5a54q5jnteo52sbgqlvnvlcpqix24gnepow2ussmxbbq",
"size": 4262857,
"number_of_files": 1,
"mime_type": "application/gzip",
"keyvalues": {},
"group_id": "01921735-7dd6-746b-b091-170e204c03d4",
"created_at": "2024-10-12T00:00:04.998938Z"
},
{
"id": "019278e0-1383-73b9-9051-4ec9db013927",
"name": "pgdata.tar.gz",
"cid": "bafybeic7agnfmxn7qktejq74xosobmurrg4yak7np2j2kfaivdxl3wt3pm",
"size": 4263052,
"number_of_files": 1,
"mime_type": "application/gzip",
"keyvalues": {},
"group_id": "01921735-7dd6-746b-b091-170e204c03d4",
"created_at": "2024-10-11T00:00:05.235771Z"
},
{
"id": "01927709-7dfd-7820-bd83-0e54b5f9ecd8",
"name": "list",
"cid": "bafkreigsvbe22ir66kqiaabfa76eunkp4mnbs5jtyd2euy66zsab3uuvm4",
"size": 443,
"number_of_files": 1,
"mime_type": "text/plain",
"keyvalues": {},
"created_at": "2024-10-10T15:26:04.181151Z"
},
{
"id": "01927707-8a16-7d7e-a862-211b4145455d",
"name": "zed-keybindings",
"cid": "bafkreicap37u35xrlrvzyhzgbn5p7mtbivfdda2qbh4wgzy4fhctoxbg5i",
"size": 19212,
"number_of_files": 1,
"mime_type": "application/json",
"keyvalues": {},
"created_at": "2024-10-10T15:23:56.04911Z"
},
{
"id": "019273b9-b556-7ea3-b793-847b69095a7a",
"name": "pgdata.tar.gz",
"cid": "bafybeia5kwvkyqwvqaifqmwmlxopysvyqs7hxvkqlzqv7jlnnv4lshx5xm",
"size": 4262964,
"number_of_files": 1,
"mime_type": "application/gzip",
"keyvalues": {},
"group_id": "01921735-7dd6-746b-b091-170e204c03d4",
"created_at": "2024-10-10T00:00:04.879244Z"
}
],
"next_page_token": "MDE5MjczYjktYjU1Ni03ZWEzLWI3OTMtODQ3YjY5MDk1YTdh"
}Trying to view this in the terminal can be pretty rough; there’s a lot to look at here. That’s the case with most APIs, and this one isn’t even that complicated. If you were trying to fetch data from the Google books API, it will be almost impossible to navigate. That’s where jq comes in.
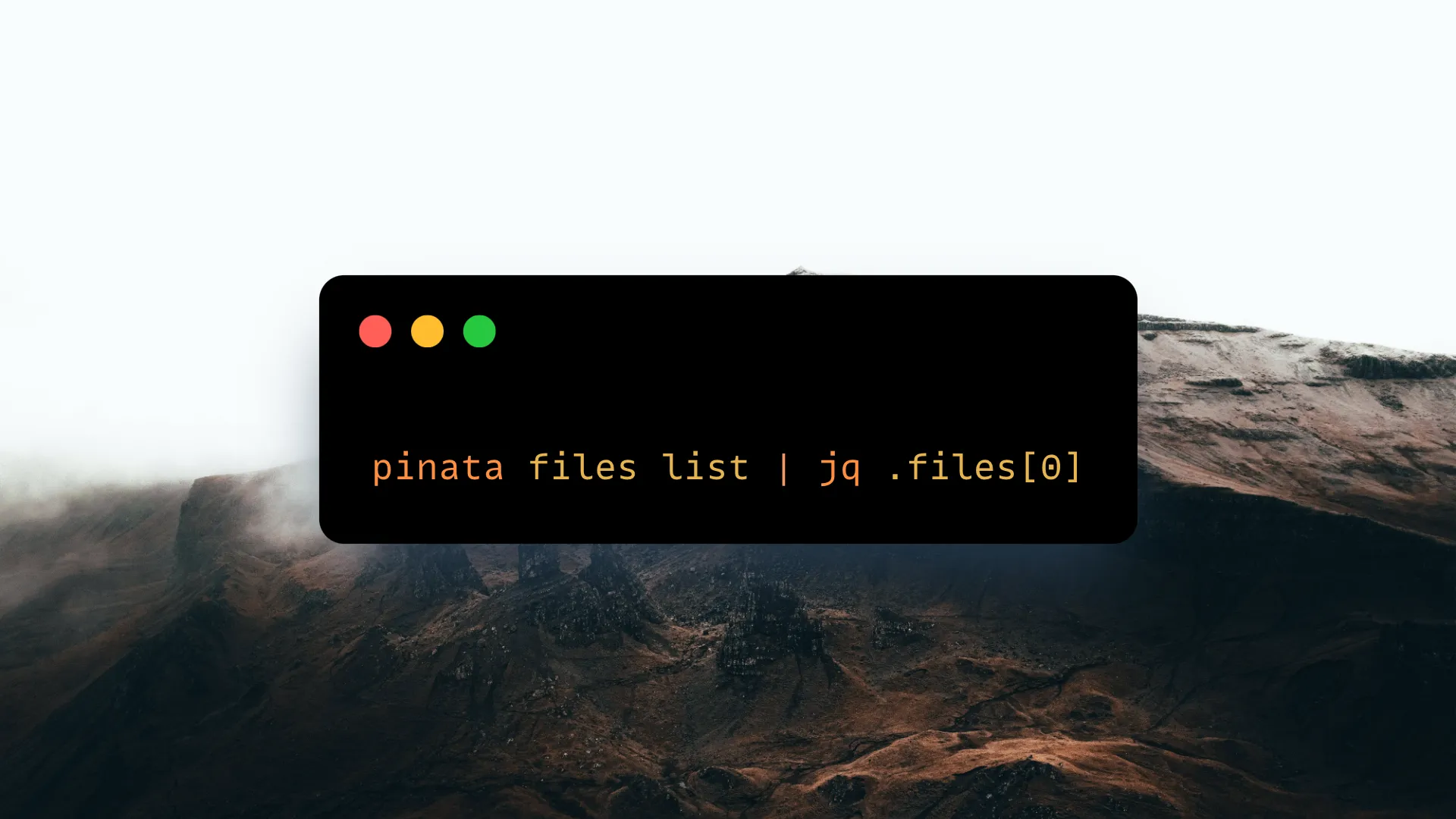
Let’s say I just wanted the first item in the files[] array; I can do that with jq by piping the results of the previous command into jq like so:
pinata files list -a 5 | jq .files[0]This will select the array and particularly the zero index of the array, just one object:
{
"id": "01927e06-6f36-7208-adb9-8cdd53ce1c98",
"name": "pgdata.tar.gz",
"cid": "bafybeicvzjxfbo5a54q5jnteo52sbgqlvnvlcpqix24gnepow2ussmxbbq",
"size": 4262857,
"number_of_files": 1,
"mime_type": "application/gzip",
"keyvalues": {},
"group_id": "01921735-7dd6-746b-b091-170e204c03d4",
"created_at": "2024-10-12T00:00:04.998938Z"
}Ok big whoop, we just reduced our results to a single object. However if we stop and think through the syntax of what we just did, we can start to see what else is possible here. What if I just wanted to grab the cid for the file that matches the name “pinnie”?
pinata files list -n pinnie | jq .files[0].cidWhat if I can to pipe that cid into another command, perhaps open it in the browser?
pinata files list -n pinnie | jq .files[0].cid | xargs pinata gateways openYou might have noticed we slipped an extra tool in here called xargs and while it’s outside the scope of this post I would highly recommend learning that tool as well. Back to jq, let’s try something else. What if I need the file names for not just the last 5 results but 50 or 100. How do we go outside just one index of an array? Just a little change in our syntax.
pinata files list | jq [.files[].name]This will give us an array of all the file names like so:
[
"pgdata.tar.gz",
"pgdata.tar.gz",
"list",
"zed-keybindings",
"pgdata.tar.gz",
"hello.txt",
"pgdata.tar.gz",
"data.json",
"b68ad739-3664-4f9f-8921-49f30ad5d615.txt",
"pgdata.tar.gz"
]Then we can pipe that into a list for later if we need it!
pinata files list | jq [.files[].name] > files.jsonThe possibilities are endless; we could continue piping commands, use a for loop in bash, etc. jq is just one of those special tools that really enables you do to more from the terminal, and that brings us to the real point of this article: learning to use CLIs.
Sadly there are many devs out their whose knowledge of the terminal stops at npm run dev at the bottom of VSCode. Maybe they go a bit further and know some commands in git, but generally people miss out on massive productivity gains that they could have had otherwise. Further, they miss out on a better understanding how all of this stuff works. I‘ve mentioned in previous posts that learning Neovim and building your config will give you a better low-level understanding of your tooling; this includes things like LSPs or syntax highlighting which are normally abstracted away from you.
Not all abstraction is bad. For example, I would much rather use Pinata than S3, but I won’t deny that it could be good to learn how to use S3. In today’s developer ecosystem it’s becoming a growing skill to learn what is worth abstracting and what isn’t. For example, I personally don’t find much value in abstracting git into a formal gui or dedicated client, however I do find value in using a tui like lazygit.
Like most things in life, there are so many gray areas in our current developer environment. Most of this comes down to preference, and it could be argued from one side to the other. Sometimes it’s more important to ship a product, sometimes it’s more important to really understand what you’re doing. Ultimately it’s up to you how far you want to go down the rabbit hole, or perhaps even more important, how open you are to the possibilities.
In my opinion the best developer is a curious one. “How does this work? Why does this work? How could I use this elsewhere?” Obviously you can’t learn everything, and you don’t necessarily need to these days, but curiosity grows your knowledge. I don’t have to write in basic at all for my job, but that hasn’t kept me from at least being curious and exploring how it works. The magic of programming is the ability to control computers and data. As was said in a recent stream with DHH and The Primeagen, “It’s more fun to be competent,” and I couldn’t agree more.
I don’t know about you, but I don’t want to settle for status quo; I want to be a wizard. So yeah, I think you should learn jq in 2024.